
Python is one of the most popular choices for machine learning. It has a low entry point, as well as precise and efficient syntax that makes it easy to use. It is open-source, portable, and easy to integrate. Python provides a range of libraries for data analytics, data visualization, and machine learning.
In this article, we will learn about the Python scikit-learn library, which is widely used for data mining, data analysis, and model building.
What is Python Scikit-Learn?
- It’s a simple and efficient tool for data mining and data analysis
- It is built on NumPy, SciPy, and Matplotlib
- It’s an open-source, commercially available BSD license
What Can We Achieve Using Python Scikit-Learn?
For the most part, users accomplish three primary tasks with scikit-learn:
1. Classification
Identifying which category an object belongs to.
Application: Spam detection
2. Regression
Predicting a continuous variable based on relevant independent variables.
Application: Stock price predictions
3. Clustering
Automatic grouping of similar objects into different clusters.
Application: Customer segmentation
How to Install Scikit-Learn?
Let’s discuss the steps to set up the Python Scikit-learn environment on your Windows operating system.
- Install Python from https://www.python.org/downloads/. After installation, open the terminal by searching for ‘cmd’. In the command line, enter python --version. It will show you the current version of Python installed.
- Install NumPy using the following link: https://sourceforge.net/projects/numpy/files/NumPy/1.10.2/, and then run the installer.
- Download SciPy installer using the link SciPy: Scientific Library for Python - Browse /scipy/0.16.1 at SourceForge.net.
- Install Pip by typing python get_pip.py in the command line terminal.
- Install scikit-learn by typing pip install scikit-learn in the command line.
What is Scikit Data Set?
For this tutorial, we will use the wine quality-red data set available on Kaggle, where you can also download the .csv file. Save the file in the same location where your Python file is saved.
Scikit-learn provides several in-built data sets for our convenience. You can visit https://scikit-learn.org/stable/datasets/index.html to learn the names of those data sets. Let’s see how to import the widely used iris plant data set.

The data set contains details about the composition of wine, as well as it's quality. For programming purposes, we will use Jupyter Notebook.
In this tutorial, we will learn the basic functionality and modules of scikit-learn using the wine data set.
Let’s start by importing the data set and the required modules.
Importing the Data Set and Modules
First, we will import the pandas' module and use the read_csv() method that pandas provide to read the required file and convert the values into data frames.
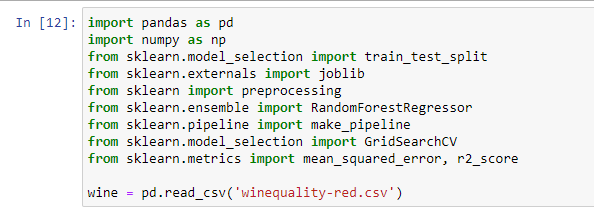
Let’s discuss each of these modules one-by-one:
- NumPy is used for algebraic and numerical calculations
- We have included pandas for working with data frames
- The model_selection module helps us to select between different models
- The preprocessing module gives us the ability to scale and transform our data
- The RandomForestRegressor is used to compare the performance metrics of our data set
Now that you have imported the data set from its source and converted that into a pandas DataFrame, let's display a few records from this DataFrame. For this, we will use the head() method.
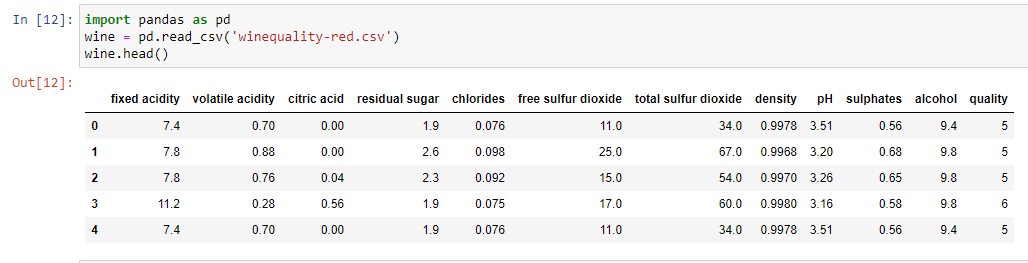
The head() method gives us the first five records from the data set.
Now, let’s look at the total number of rows and columns in the data.

Our data set consists of 1599 samples and 12 features, including our target feature.
All features include the following:
- quality(target)
- fixed acidity
- volatile acidity
- citric acid
- residual sugar
- chlorides
- free sulfur dioxide
- total sulfur dioxide
- density
- pH
- sulfates
- alcohol
Learn top skills demanded in the industry, including Angular, Spring Boot, Hibernate, Servlets, and JSPs, and SOA to build highly web scalable apps with the Full Stack Java Developer Masters Program.
Training Sets and Test Sets
Splitting the data into training and test sets are vital to estimating your model's performance.
A training set is used to test our algorithm to build a model.
A testing set is used to test our model to see how accurate our predictions are.
Let’s separate our target (y) and our training (x) features, and split them into the train and test sets. We will use the scikit-learn train_test_split() function for splitting.

Take Your Data Scientist Skills to the Next Level
With the Data Scientist Master’s Program from IBMExplore ProgramPreprocessing Data
Data preprocessing is the process in which we make the data suitable to be performed over a model with less effort. It is the initial and most important process that enhances the quality of the model.
What is Standardization?
Standardization is a technique that is performed as a preprocessing step—before machine learning models are applied—to standardize the range of input representing data features.
We will be using Transformer API for preprocessing code, which makes the model performance more realistic.
![]()
What is Hyperparameter?
- Hyperparameters define the higher-level concepts, such as complexity or capacity to learn
- It cannot be learned directly from the data in the standard model training process and needs to be predefined
Examples of hyperparameters include:
- Learning rate
- Number of clusters in clustering algorithms
You can see the list of tunable hyperparameters in the following way:
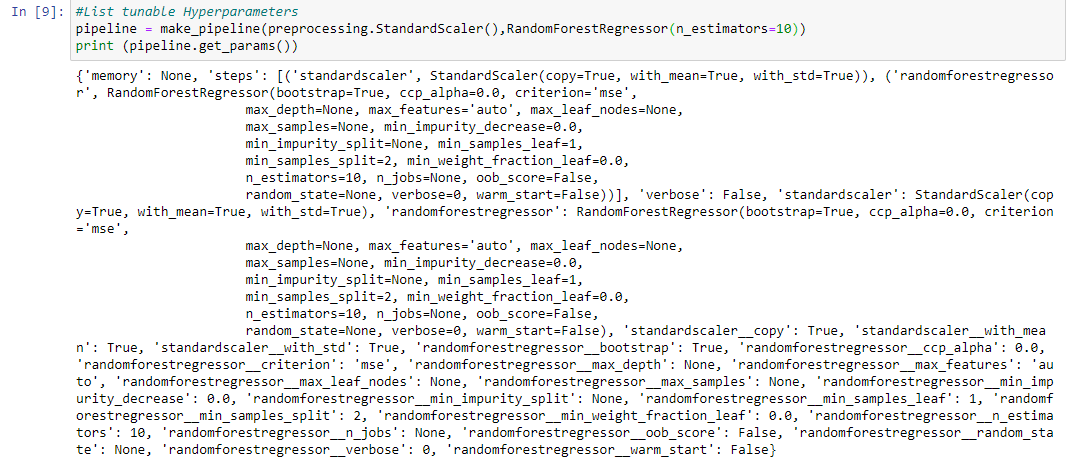
The make_pipeline() function is used to combine a preprocessor with a classifier.
Let’s declare the hyperparameters.

What is Cross-Validation?
Cross-validation is an important evaluation technique used to assess the generalization performance of a machine learning model. To avoid overfitting, the data set is usually divided into N random parts with equal volume.


GridSearchCV performs the cross-validation across the entire grid.
Evaluate Model Pipeline
Now it’s time to evaluate the model performance. For this, we import the metrics we used earlier.
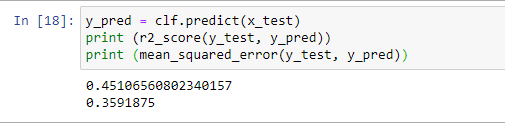
The r2_score function is used to calculate the variance of the dependent variable for the independent variable.
Mean_squared_error calculates the average of the square of the errors.
To assess if the performance is sufficient, we return to the goal of the model that it was designed for.
Do not forget to save the model for future use.

Learn data operations in Python, strings, conditional statements, error handling, and the commonly used Python web framework Django with the Python Training course.
Conclusion
In this Python scikit-learn article, we discussed the basic concepts of scikit-learn. We looked at how to import a data set and its different functions. We went through hyperparameters, preprocessing, and cross-validation techniques.
If you have any questions, please share them in the comments section, and we'll have our experts answer them for you.
Want to Learn More About Machine Learning?
Professionals who understand how to work with machine learning tools and techniques are in super high demand today. If you want to upskill in this powerful technology to boost your career, check out our AI and ML Certification and Machine Learning Course today!
